provider-agnostic LLM failover · single-tenant
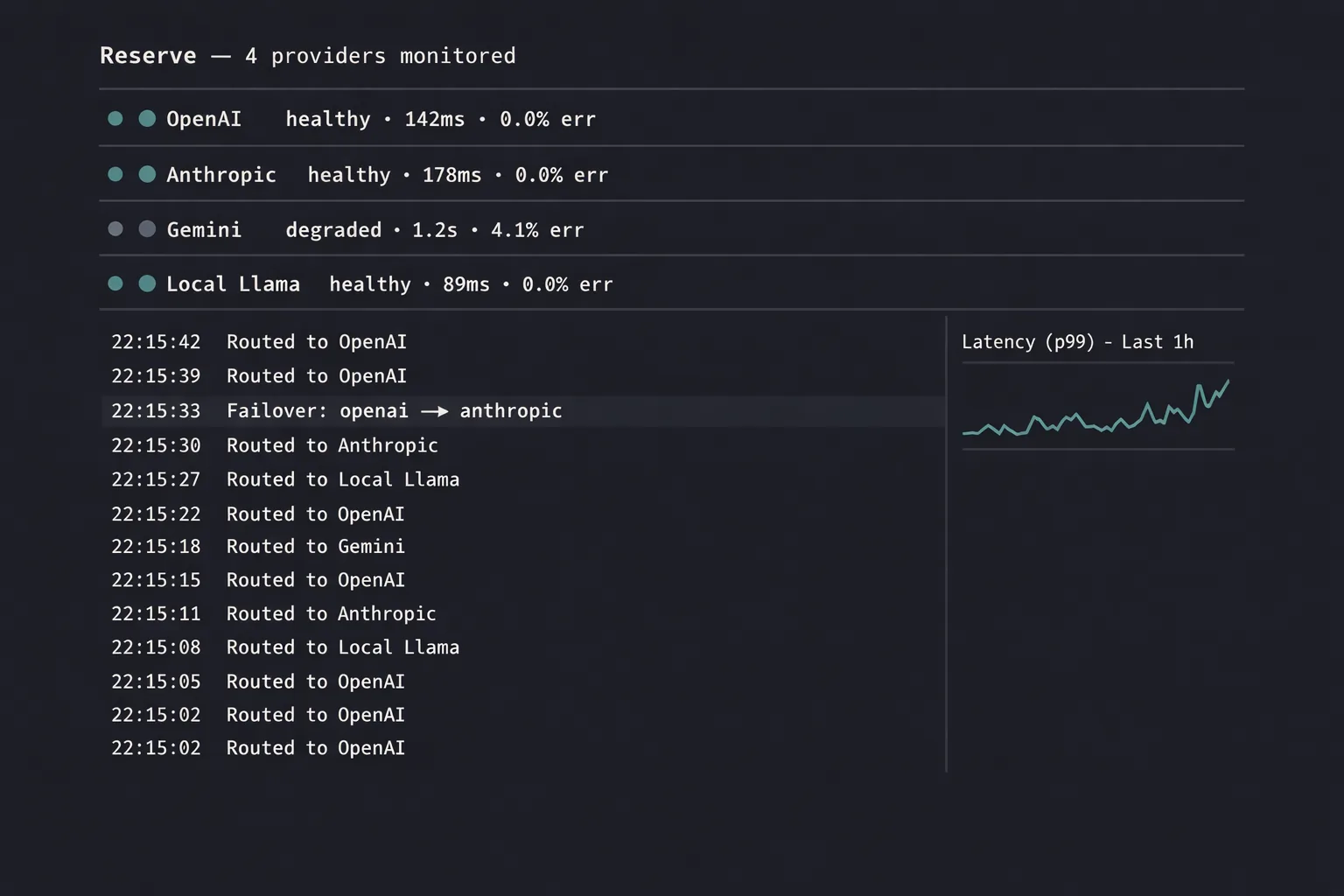
Reserve
- Built for:
- Apps where an LLM call sits on the critical path and a 429 from the primary provider means a broken UX, not just slower output.
- Not built for:
- Workloads where the answer must come from a specific model, full stop. Reserve assumes you can route to a peer of the primary if the primary is down.
The promise of a single AI provider is that you don’t have to think about reliability. The reality is that every provider has bad days, rate-limit cliffs, and quiet quality regressions, and your app gets to discover those at the worst possible moment. Reserve sits in front and reroutes around them.
The problem
Most production AI apps have a single point of failure: the model provider. When that provider rate-limits, throws 5xx, or silently regresses on a model version, the app degrades or breaks — and the engineering team finds out from users, not from monitoring. The default state of LLM infrastructure is “hopeful.”
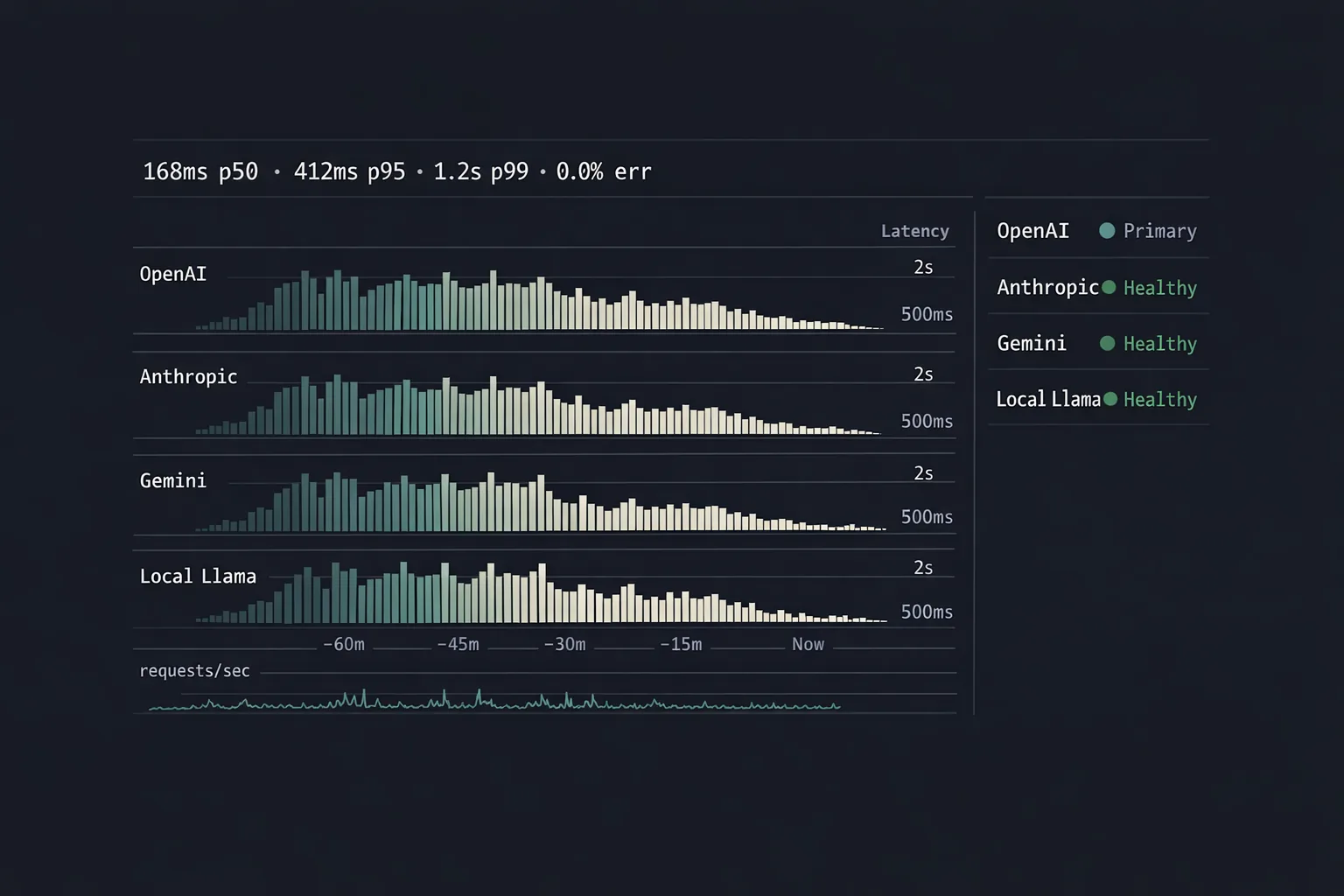
Reserve makes the failover explicit and observable. Each request runs against a primary; if the primary errors, slows past a budget, or trips a quality gate, the request retries on a peer. The application layer never sees the difference; the operations layer sees the whole story.
Decisions
kept
A typed capability surface for providers, not a string-keyed registry. Adding Anthropic, OpenAI, Gemini, Mistral, and a self-hosted Ollama means a Python protocol class and a few hundred lines of adapter — not a config-driven black hole.
cut
Streaming-aware failover mid-response. If the primary fails halfway through a streaming completion, Reserve does not silently restart on a peer — the partial response is surfaced and the application chooses. Hidden mid-stream switches are a debuggability disaster.
kept
A circuit breaker per provider, not per route. When OpenAI is having an incident, every route through OpenAI is suspect, not just the one that just failed. The breaker tracks at the provider level and opens for everyone using that provider, fast.
System
| Layer | Implementation | Purpose |
|---|---|---|
| Edge | FastAPI + uvicorn | Single OpenAI-compatible endpoint surface |
| Routing | Provider protocol | Typed adapters · per-provider quotas |
| Breakers | Redis-backed | Per-provider circuit · sliding window error rate |
| Quality | Sampled judge | 1% of responses graded; regressions flag |
| Audit | Postgres | Every request · provider · latency · outcome |
| Metrics | OpenTelemetry | p50/p95/p99 per provider per minute |
# A provider is a typed capability surface, not a config blob.
# Adding a peer means implementing two methods + a circuit name —
# the rest of Reserve doesn't change.
class Provider(Protocol):
name: str
breaker_key: str
async def complete(
self,
req: ChatRequest,
budget: Budget,
) -> ChatResponse: ...
async def health(self) -> HealthSignal: ...
# Failover is explicit: try primary, observe, fall back to peer.
async def route(req: ChatRequest) -> ChatResponse:
primary, peers = pick(req)
if breaker.open(primary.breaker_key):
return await failover(peers, req)
try:
return await primary.complete(req, budget=req.budget)
except (Timeout, RateLimit, ProviderError) as e:
breaker.record(primary.breaker_key, e)
return await failover(peers, req)
{"t":"02:14:09Z","provider":"openai","event":"trip","window":"30s","err_rate":0.41,"reason":"5xx"}
{"t":"02:14:09Z","provider":"openai","state":"open","cooldown_until":"02:14:39Z"}
{"t":"02:14:09Z","route":"chat","peer":"anthropic","reason":"failover"}
{"t":"02:14:39Z","provider":"openai","event":"probe","state":"half-open"}
{"t":"02:14:40Z","provider":"openai","event":"recover","state":"closed","probe_ms":612}
{"t":"02:14:40Z","route":"chat","peer":"openai","reason":"primary-restored"}

Acknowledgments
Reserve stands on FastAPI, Redis, Postgres, OpenTelemetry, and the published OpenAI-compatible API surface that lets a router layer be agnostic to which actual model handles the work.
← Index